IoT Project Retrospective
Part 1, Software
I've been running a Internet of Things (IoT) project for about 6 years continuously, and the components / solution has evolved considerably, whilst the over function has remained the same. It's provided me with a neat springboard to learn and try out different technologies as they evolve.
The conceptual architecture is quite simple:
- A home network of sensors (temp, pressure etc) and switches (sprinklers).
- A central hub to collate the sensor data, and to act on it, either real-time (IFTTT style) or scheduled.
Since its inception the core technologies have been based around the following hardware:
- ATTiny micro-controller chips to embed logic in the end devices (nodes).
- XBee mesh networking with S2 modules (typically standard ZB ones and pro ZB for the controller).
- Local hub that acts as both a controller and bridge between the XBee mesh network and IP based comms.
Iteration #1
2013-2016, "The Arduino Years"
Rudimentary but a bit flaky, using a Ethernet based arduino as the controller/bridge, pinging the sensor "log" data to a remote backend - PHP based web app hosted on Register1. This same back-end existed until iteration #3 when I moved it to AWS.
At this point, the project was sensor only, hence just spewing out log reads every 15 mins for a small number of sensor nodes. Since the compute power on the Arduino was low, it was simply using AT command based commands rather than API, and hence receiving a string from the sensor nodes (CSV) and passing that up to a simple CSV based API. Not particularly elegant, but it worked.
Whilst this served a purpose, the processing power and durability of using an Ethernet Arduino as the local hub started to creak when I moved beyond just logging sensor readings (ie control). Time for more horsepower!
Iteration #2
2016-2018, "The RPi Years"
This iteration was actually the most stable in terms of change as it just worked and I kinda lost interest in the project for while.
Moving to RPI had enabled the project to stretch its legs a bit and use:
- Python on the RPI as the main processor app (ran as a daemon).
- Moved the controller XBee to use API mode rather than AT command (via the XBee module).
Iteration #3
2018-2020, "The AWS Years"
Late 2017 / early 2018, I started learning working with AWS components for work, so what better way to learn, than through a pet project.
This was very much a back-end migration piece where the DB, logic, API's and UI where ported across to AWS, specifically:
- Angular v1 UI (hosted on Apache).
- Node based API layer (PM2, and proxied through from Apache).
- MySQL DB.
- UI+DB+API hosted on EC2 instance.
- Use of AWS IoT Core as the MQTT protocol between the RPi and the back-end.
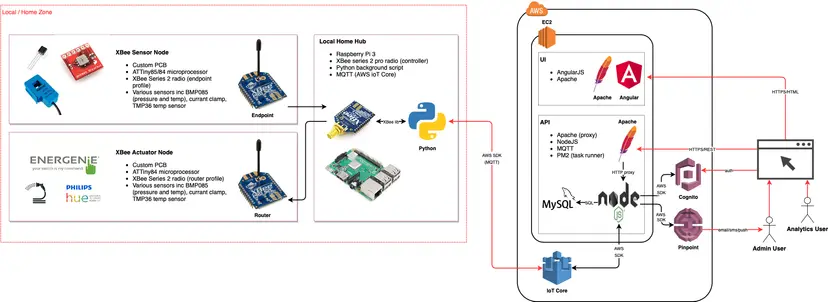 Iot Architecture, v3
Iot Architecture, v3Once migrated and stable, again I lost interest in it, primarily as it was just working fine; it was taking readings, producing some nice graphs (HighChart) and dashboards, plus it was watering the garden flawlessly!
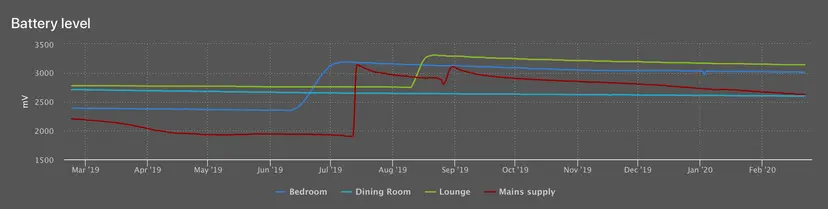 HighCharts graph showing sensor node battery lifespan
HighCharts graph showing sensor node battery lifespanIteration #4
2020+, "Cloud Native"
This brings us right up to date with the current iteration, which again was triggered as a work based learning exercise, as I'd been running a project that was really "doing cloud native properly", ie serverless architecture, infrastructure as code, full CI/CD pipelines and the the kitchen sink. So again, the functionality got picked up, refactored and in many cases completely re-architected:
- React UI hosted on S3 / CloudFront.
- API Gateway + Cognito + Lambda as the API layer.
- S3 as the data source - this took a lot of rethinking to move away from RDBMS.
- DynamoDB for control data objects.
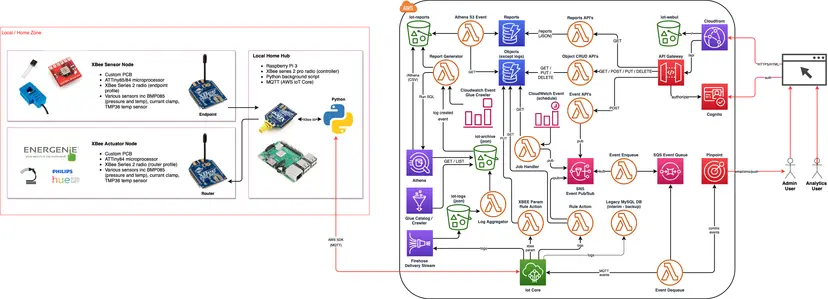 Iot Architecture, v4
Iot Architecture, v4The most sizable change was to move away from a RDBMS and use S3 + Glue + Athena for the graphing. This probably warrants a series on its own, but to summarize:
- Raw JSON logs pushed into S3 objects from a Firehose delivery stream (allows for batching).
- Files rolled into a single monthly file via log aggregator event.
- Glue database and table defined onto of the aggregated log files.
- Athena used to query the data periodically and caches it in DynamoDB, which is then consumed by the UI.
Couple of key points around this architecture:
- Athena is performant, but not that quick to query and return data in real-time (~2-3 seconds).
- Athena performance and S3 cost (number of object reads) is directly related to how you partition and the size of each partition. In this case, a year partition with 12x files per year is fine. Any finer (day files, for example) and the cost of S3 reads rises massively. Any more coarse grained and each query reads too much data.
- Specific examples; wrong = S3 monthly cost of £60-£70 per month, right = < 50p per month.
Iteration #5
Future
Unclear at this point, but would like to incorporate some ML and predictive analysis on the data, in particularly battery cycles. Beyond that, who knows!
More posts in this series:
- Part 1, Software
- Part 2, Hardware